
MIDJOURNEY V6 est arrivé !

Salut les artistes numériques augmentés, les amateurs de belles images, les techniciens du prompt et les autres. Bienvenue dans cette nouvelle édition de GENERATIVE, la grosse newsletter hebdomadaire qui résume l’actualité de l’IA générative, vous présente des outils, des projets et des acteurs de l’écosystème.
La sortie tant attendue de la 6e version du roi incontesté de la génération d’images IA, j’ai nommé Midjourney, est arrivée jeudi matin, chamboulant le programme éditorial de cette édition. Je m’adapte avec réactivité en vous proposant un dossier qui présente toutes les nouveautés de cette version ainsi que mon analyse.
Let’s go !
Au sommaire cette semaine :
✔️ Les news de la semaine
✔️ Le guide du prompting d’Open AI
✔️ Midjourney v6 : le dossier pour tout savoir !

Les news de la semaine
Google FunSearch
Google DeepMind vient de sortir un nouveau chatbot, FunSearch, basé sur Google PaLM2 qui surpasse les mathématiciens humains. FunSearch serait capable de générer des millions de solutions potentielles, et serait même capable de développer des programmes informatiques pour résoudre des problèmes. Selon le mathématicien Jordan Ellenberg, cette technologie ne remplacera pas les humains, mais agira comme un multiplicateur de force, ouvrant la voie à de nouvelles formes de collaboration homme-machine.
Source
Bard sous amphétamines
Google toujours, aurait franchi une étape importante avec Bard qui intègre désormais Gemini. Cette version, plus avancée, produit des réponses beaucoup plus détaillées et humaines que précédemment. Les tests révèlent que Gemini surclasse la version classique en particulier en génération de texte et de code (ce qui n’était pas très difficile, ajouteront les mauvaises langues). Disponible uniquement aux US pour le moment (en Europe avec un VPN), Bard Advanced avec Gemini Ultra devrait être déployé dans le monde courant 2024.
Source
EasyFakes
Doit-on s'inquiéter du fait qu'il devient de plus en plus facile de générer des deepfakes de n'importe qui en temps réel ?
Je vous laisse vous forger une opinion en allant faire un tour sur cette plateforme : https://www.fal.ai/camera
Amazon et la génération d’images
Amazon lance Titan Image Generation, un générateur d'images par intelligence artificielle destiné aux professionnels. Intégré à son service cloud Bedrock, il permet de créer des visuels “de qualité” (on a hâte de vérifier) à partir de textes ou d'images existantes. Paramétrable finement, avec des garanties contre les dérives, Titan cible les entreprises pour créer des images sur-mesure, conformes à leur marque et à leurs besoins. Une alternative business à des outils grand public comme Midjourney.

Prompt-to-video 2.0
W.A.L.T se présente comme une intelligence artificielle révolutionnaire développée par l'université Stanford, capable de générer des vidéos photoréalistes à partir de textes ou d'images. Utilisant une approche novatrice d'apprentissage, cette IA crée des vidéos fluides en 3D, démontrant des capacités impressionnantes. Par rapport à Runway Gen-2, Pika ou d’autres concurrents, W.A.L.T. se distingue par le photoréalisme de la plupart de ses générations. A suivre de très près…
VideoPoet
De manière un peu moins impressionnante, Google Research a présenté VideoPoet, un modèle de génération de vidéos. En plus de proposer du prompt-to-video, il offre des fonctionnalités telles que la conversion d’image en vidéo, du montage vidéo et de la génération audio.
Optimus Prime, 2e
Tesla a récemment dévoilé la 2e génération de son robot humanoïde Optimus, qui montre des améliorations significatives. Plus rapide de 30% et 10% plus léger, ce prototype possède des mains améliorées avec un sens du toucher dans chaque doigt, lui permettant de manipuler des objets délicats comme des œufs sans les casser.
Mes enfants ne peuvent pas en dire autant.
Ce robot, formé avec des réseaux de neurones de bout en bout, peut exécuter des tâches autonomes comme trier des objets. Tesla envisage d'utiliser Optimus dans ses usines de véhicules et éventuellement le commercialiser. Toujours modeste, Elon Musk estime que la demande pour ces robots pourrait atteindre des milliards d'unités.
Source
Bien utiliser l’IA en entreprise
Une récente étude de Salesforce et YouGov révèle une utilisation "éthiquement discutable" de l'IA générative en entreprise. 58% des employés français utilisent l'IA générative en dehors des directives de leur entreprise, et 87% indiquent que leur employeur n'a pas de politique claire sur son usage. Malgré le manque de cadre, 68% des salariés français se sentent plus productifs et 63% plus impliqués grâce à l'IA générative. Cependant, 71% ont présenté des travaux réalisés par l'IA comme les leurs. L'étude souligne la nécessité pour les entreprises de fournir des directives et formations pour une utilisation responsable et éthique de l'IA générative.
Mistral again and again
Cela fait quelques mois déjà que nous partons régulièrement ici de Mistral, la startup française qui a récemment fait sensation en lançant Mixtral-8x7B, un modèle de langage qui surpasserait GPT-3.5 et Llama 2.
Fondée il y a 6 mois à Paris, Mistral a déjà levé 385 millions d'euros et atteint une capitalisation de 2 milliards de dollars. Leur dernier modèle, Mixtral-8x7B, utilise une technique appelée "Mixture of Experts" et se caractérise par une efficacité accrue grâce à l'utilisation partielle de ses 45 milliards de paramètres. Disponible en open source, ce modèle sans filtre de censure est accessible via une API payante sur la plateforme développeur de Mistral.
ou gratuitement sur diverses plateformes comme HuggingFace
et Perplexity Labs.
Une autre démo est également disponible sur Vercel
L’empreinte carbone des “shoots IA”
Jonathan Gilbert, co-fondateur de Detroit, une agence de création IA, a réalisé récemment une comparaison des émissions de carbone entre la production photographique traditionnelle et celle réalisée par l'IA. Pour une production photographique traditionnelle à Marseille (au hasard), impliquant cinq personnes pendant trois jours, l'émission totale de CO2 est de 672 kg. En revanche, une production utilisant l'IA pour générer des images émet seulement 0.6 grammes de CO2. Faites le calcul : la production traditionnelle émettrait environ 1120 fois plus de CO2 dans l’hypothèse d’un tournage en Europe et bien davantage (36250 fois +) en Afrique du Sud. La recherche s'appuie sur des sources telles que l'ADEME et l'Agence internationale de l'énergie.
Source
Runway again
Runway lance Téléscope Magazine, une exploration de l'art, de la technologie et de la créativité humaine. Accessible gratuitement :
https://www.telescopemagazine.com/
Stable Video Diffusion
En parlant de Runway, Stability Ai, la start up a l'origine de Stable Diffusion a sorti un geverateur de vidéos nommé : Stable Video Diffusion. Le modèle peut générer 2 secondes de vidéo, comprenant 25 images générées et 24 images interpolées, en un temps moyen de 41 secondes.
À ceux qui pensent “2 secondes ? C'est un peu court jeune homme ! “ en comparaison avec Runway Gen-2 qui permet de générer jusqu'a 16 secondes, je répondrai deux choses :
1-Ce n'est que le début, ça va progresser
2- c'est de l'open source !
Les développeurs peuvent accéder à l’API dès maintenant sur la Plateforme des Développeurs de Stability AI.
Runway toujours
Runway n’en finit plus de proposer de nouvelles fonctionnalités avec cette option qui permet de compositer deux images entre elles.
Busted !
ByteDance, créateur de TikTok, a été pris en flagrant délit d'utilisation secrète des outils d'OpenAI, notamment GPT-4, pour développer son propre modèle d'intelligence artificielle. Cette affaire, révélée par The Verge, montre que ByteDance exploitait les outils GPT via Microsoft Azure pour son projet "Seed". Suite à la publication de l'article, Microsoft a suspendu le compte de ByteDance pour enquête. TikTok, ayant annoncé des projets IA comme Tako et Grace, pourrait voir ses ambitions en IA freinées par les répercussions de cette affaire.
Prison Break
Incarcéré depuis le mois d’août, L'ex-Premier ministre pakistanais Imran Khan a utilisé l'IA pour diffuser un discours virtuel malgré sa détention. Grâce à une reconstitution de sa voix par l'IA d'ElevenLabs, basée sur ses notes, son parti PTI a relayé un message de quatre minutes sur les réseaux sociaux, atteignant 4,5 millions de personnes. Ce fait démontre l'impact croissant des deepfakes en politique, en tant qu’outils performants pour manipuler l’opinion publique. Restons vigilants.
Runway everywhere
Depuis quelques jours, Runway a déployé une fonctionnalité de text-to-speech dans son interface. Il n’y a que des voix anglophones pour le moment, et ça fonctionne plutôt pas mal. Le créatif IA a réalisé une petite vidéo pour l’occasion :
Le guide du prompt engineering
Open AI a sorti récemment son propre guide du Prompt Engineering.
“One guide to rule them all”.
Voici un résumé des 6 stratégies recommandées pour obtenir de meilleurs résultats lors de la formulation des prompts pour GPT :
Rédiger des Instructions Claires :
Être spécifique : la clarté des instructions conduit à des résultats plus pertinents.
Définir la longueur et la complexité de la sortie souhaitée.
Spécifier les formats préférés.
Minimiser l'ambiguïté pour améliorer la précision du modèle.
Fournir un Texte de Référence :
Contrer les éventuelles hallucinations avec des matériaux de référence concrets.
Les textes de référence guident le modèle vers des réponses précises et fiables.
Diviser les Tâches Complexes en Sous-tâches Plus Simples :
Décomposer les tâches pour réduire les erreurs et simplifier votre communication avec chatGPT
Considérer les tâches comme des flux de travail de étapes plus simples et interconnectées.
Donner au Modèle le Temps de "Réfléchir" :
Permettre au modèle de traiter et de raisonner, à l'instar d'un humain résolvant un problème complexe.
Encourager une approche "chaîne de pensée" pour un raisonnement plus précis.
Utiliser des Outils Externes :
Compléter les capacités du modèle avec des outils spécialisés pour des tâches spécifiques.
Tirer parti de ressources comme les systèmes de récupération de texte ou les moteurs d'exécution de code.
Tester les Changements de Manière Systématique :
Mesurer les améliorations avec une approche de test complète.
S'assurer que les modifications conduisent à des améliorations globales de la performance.
A vos prompts ! Le guide complet est dispo ICI.MIDJOURNEY V6
Très attendue dans les milieux créatifs, la sortie de la 6e version de Midjourney est clairement LA grosse news de cette fin d’année.
J’ai commencé à la tester et suis évidemment très enthousiaste. Je tiens toutefois à me démarquer des influenceurs Twitter qui disent que tout est génial, et conserver un regard critique et objectif en vous faisant partager mes observations.
N.B. La v6 actuellement disponible est une version bêta. Elle est susceptible d’évoluer dans les prochaines semaines.Koidneuf Docteur ?
La grande nouveauté de la v6 selon David Holz, le founder de Midjourney, serait une meilleure compréhension des prompts. Terminés les phrases alambiquées, les mots aléatoires et les “junk token” (“8k”, “4k”, “photorealistic”…).
Nous pourrions assister à une nouvelle façon de prompter Midjourney, avec des structures qui ressembleraient à celle-ci
Crédit : Tatiana Tsiguleva
🌟Précision améliorée dans le suivi des prompts : Cette mise à jour offrirait une meilleure précision dans la façon dont le modèle suit et interprète les prompts en langage naturel, permettant ainsi une meilleure adéquation entre les résultats générés et les consignes saisies.
🌟 La taille maximale des prompts passe désormais à 350 (!) mots.
🌟 Il serait également possible de spécifier la composition précise de l’image avec des mots.
🌟 Midjourney V6 est capable de comprendre les nuances de ponctuation et de grammaire. (par exemple : "Un panda mange, tire et part.")🌟 Vous pouvez utiliser la V6 pour créer des bandes dessinées.
🌟 Certains négatifs en langage naturel fonctionnent désormais.
🌟 Vous pouvez ajouter un cadre ou une bordure autour d'une image simplement en la décrivant.
On notera dans les images ci dessous comme le modèle respecte bien le style visuels indiqué (“Kodak Portra 160”, “vintage color grading”). On notera également le physique moins top model de la jeune femme, contrairement aux générations “Beautiful People Only” proposées par la v5 (qui en revanche, interprète lieux le “wide angle”)
Wide angle selfie of a woman in greenland wearing winter gear, icy landscape, shot with Kodak Portra 160 film, vintage color grading --style raw --v 6.0 
Wide angle selfie of a woman in greenland wearing winter gear, icy landscape, shot with Kodak Portra 160 film, vintage color grading --style raw --v 5.2
DANS LE MONDE RÉEL (et ce n’est qu’une première impression qui demandera à être affinée avec le temps), j’ai le sentiment que la v6 met l’accent sur le réalisme là où la v5 proposait des rendus plus spectaculaires.
Un exemple avec un même prompt utilisé avec les 2 versions.
cinematic photography of a talented snowboarder jumping with astonishing agility | movements frozen in time | defying gravity, attracting a lively crowd of onlookers | snow, mountains background --ar 16:9 --v 6.0 --style raw 
cinematic photography of a talented snowboarder jumping with astonishing agility | movements frozen in time | defying gravity, attracting a lively crowd of onlookers | snow, mountains background --ar 16:9 --v 5.2 --style raw Même exemple avec du skate

v6 
v5 Cohérence et connaissances du modèle améliorées : La version 6 affiche une amélioration de la cohérence dans les résultats générés et une meilleure compréhension des connaissances incorporées dans le modèle.
Avec d’excellentes performances visuelles non seulement avec les rendus photos, amis aussi picturaux, 3D ou illustratifs.

Exemple de cohérence avec modification du sujet dans le prompt :
L'utilisation de « Vary » aurait désormais beaucoup plus de puissance, car les images sont supposées conserver une meilleure cohérence. Dans cet exemple de l’utilisateur TechHalla, vous pouvez voir comment, en changeant le véhicule dans l'invite d'origine d'une camionnette, les images conservent beaucoup plus de cohérence.









Gestion du multi prompting : Késaco ?

Crédit : Tatiana Tsiguleva Une meilleure représentation des émotions : Il était compliqué d’obtenir des émotions précises sur les visages de personnages générés par Midjourney v5. La v6 adresse ce problème avec des émotions plus réalistes :



Toujours à l’aise pour représenter des visages célèbres

Capacité de générer du texte : Il est maintenant possible d'inclure du texte dans les créations. Pour de meilleurs résultats, il est recommandé d'encadrer le texte de guillemets et d'utiliser les options --style raw ou de réduire les valeurs de --stylize.


DANS LE MONDE RÉEL : ça fonctionne, mais pas à tous les coups

Options améliorées d'upscaling : La version 6 propose deux options d'upscaling 'subtle' et 'creatives', permettant de doubler la résolution des images. Ces options sont accessibles via des boutons étiquetés U1/U2/U3/U4 sous les images après sélection. Le “Subtle” a tendance à trop lisser l’image à mon goût, je lui préfère l’upscale “créative”, au rendu plus détaillé. En revanche, il faut s’armer de patience, le processus est assez lent.

Fonctionnalités de lancement : Parmi les fonctionnalités incluses à ce jour, citons --ar, --chaos, --weird, --tile, --stylize, --style raw, Vary (subtile/forte), Remix, /blend, /describe (uniquement v5).

Credit : Your AI Animation Guy Prochaines fonctionnalités : Des fonctionnalités telles que Pan, Zoom, Vary (région), /tune, /describe (v6) devraient être bientôt disponibles. “vary Region” sera bien utilise pour pallier à certains bugs anatomiques encore un peu trop présents. Mais cela est-il dû à un prompting v5 inapproprié à la v6 ?

Et prompter en langage naturel alors ? J’ai essayé et je dois avouer que ça fonctionne plutôt bien.
Prompt : “Three different best friends sitting close together on a park bench. The friend in the middle is a cheerful blonde Caucasian woman wearing jeans and a green tank-top. The friend on the right is a serious African American man dressed in a tuxedo. The friend on the left is a laughing Indian woman wearing orange Hindi traditional robes. In the background, the empty park contains some old live oak trees. “
Comment l'essayer via Discord : Pour tester la version 6, il suffit de se rendre sur Discord et de suivre l'une des deux options : taper /settings et sélectionner v6 dans le menu déroulant, ou inclure --v 6 à la fin des invites.

Dans certains contextes, il est parfois difficile de distinguer les 2 versions. Exemple avec les images ci-dessous : saurez vous dire laquelle est la v6 ?

En résumé, il faudra du temps et beaucoup de générations pour évaluer cette nouvelle version à sa juste valeur. Si les premiers tests surprennent, étonnent, enthousiasment, déçoivent parfois, il est important de recontextualiser cette v6 comme une étape supplémentaire dans les progrès constants des modèles de génération d’image depuis la sortie de DALL-E premier du nom en 2021.
Pour mémoire, cette comparaison de Nick St-Pierre autour d’un même prompt, à une année d’intervalle :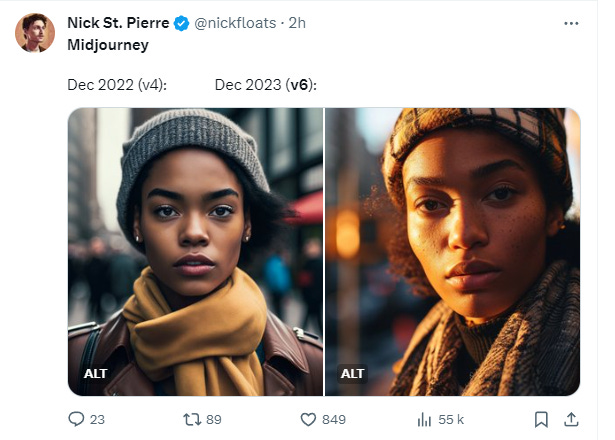






Mon avis de professionnel de l’image
(P.S. Pour la photo des lions, la v6 était en haut)
Il y a une évidence indéniable dans l'augmentation du degré de photoréalisme des images générées par ce nouveau modèle.

J’ai également le sentiment d’images globalement plus “riches” car plus colorées et texturées que celles de la v5.2.
Les compositions sont également différentes. Moins symétriques sur la v6, probablement plus variées, mais également moins dynamiques.
En revanche, ce progrès s’accompagne d’un traitement numérique des images, que je trouve moins naturel qu’avec la v5. Je pense notamment au “sharpening” (accentuation de la netteté) excessif et au HDR (High Dynamic Range), traitement typique des photos smartphones, au rendu beaucoup trop artificiel à mon goût.
Exemple par l’image :


Le rendu de la photo du haut est beaucoup plus naturel : l’image est moins saturée, moins artificiellement nette, il y a davantage de détail dans les basses lumières. L’image du bas semble avoir été longuement retouchée dans Photoshop. Ce traitement ne conviendra pas à tous types de projets.
On notera en revanche une meilleure séparation colorimétrique dans les images générées avec la v6. La v5 avait en effet tendance à appliquer une dominante de couleur (souvent jaune) aux images :


Une autre question que je me pose, c’est l’avenir d’upscalers tels que Magnific AI maintenant que Midjourney propose par défaut des images très sensiblement plus nettes qu’avec la v5.
Ce besoin va t-il perdurer ou s’éclipser ? Magnific AI devrai t-il se réinventer pour survivre ? Un exemple avec cette photo v6 non upscalée :

En conclusion, cette v6 offre un nouveau terrain d’exploration aux utilisateurs de la v5, qui devront très probablement revoir leurs habitudes de prompting pour pouvoir tirer le meilleur de l’outil.
Personnellement, je trouve ce changement stimulant, même si je demeure partagé sur les choix artistiques en termes de rendus qui deviennent très paradoxalement plus précis et en même temps étrangement plus artificiels.
Cette transition pourrait nécessiter un temps d'adaptation, mais elle promet également des visuels étonnants à venir… et une stimulation de la concurrence dans la course au titre de dauphin.
La surprise viendra t-elle d’Adobe Firefly 3 ? De Musavir v2 ? de DALL-E 4 ? De Stable Diffusion XXL ? De Google Imagen ? A défaut de spéculer sur un nouveau champion, je vous invite à explorer cette nouvelle version de Midjourney qui semble avoir beaucoup à dévoiler.
Cette édition est terminée, merci de l’avoir lue jusqu’au bout, Si elle vous a plu, vous pouvez la partager en cliquant juste ici :
Vous pouvez également me suivre sur LinkedIn et activer la cloche 🔔, je poste régulièrement sur l’intelligence artificielle générative. Vous pouvez également me contacter pour toute proposition de création, intervention, conférence, projet, formation liée à l’intelligence artificielle générative.
Et n’oubliez pas de vous abonner pour ne rien rater des prochaines éditions 👇
Je vous souhaite d’excellentes fêtes de fin d’années !