


Des updates, des effets et des projets publicitaires

Salut les humains, les augmentés, les robots, les cyborgs, les chatbots et les androïdes, et bienvenue dans cette 78e édition de GENERATIVE, la grosse newsltter hebdomadaire qui parle de créativité et d’IA Generative et vice versa.
Cette semaine nous revenons sur les news immanquables en collaboration avec Caroline Thireau, des expérimentations avec la nouvelle version du générateur de vidéos IA Pika 1.5, suivies d’un Behind The Scenes (BTS, a.k.a. “Making Of” en bon français) de ma dernière collaboration IA avec la marque Tediber et d’une comédie politique plutôt réussie !

Let’s go !
Les news de la semaine
🔹PIKA 1.5 is in da house
Pika sort sa version 1.5. La mise à jour revendique des avancées en réalisme, des mouvements plus naturels, des expressions faciales détaillées et des gestes affinés. Mais le clou du spectacle, ce qui emplit nos timeline depuis mercredi, c’est la fameuse option « Pikaffects ». Très fun, mais je sens que tout le monde va très rapidement se lasser.
Beaucoup de lenteur pour les générations depuis cette sortie…. Cette courte vidéo de Gilles qui a pris la grosse tête a mouliné toute la nuit :
🔹A new kid on the block
ByteDance (qui possède TikTok) a dévoilé deux nouveaux modèles , Doubao-PixelDance et Doubao-Seaweed, axés sur la création de vidéos à partir de textes et d'images. Doubao-Seaweed peut générer des clips de 30 secondes, en se concentrant sur la stabilité des sujets et du style à travers les séquences. Cette initiative reflète les efforts des entreprises chinoises pour rattraper leur retard face aux leaders occidentaux du marché, comme Runway.
🔹LipDub AI
Un nouvel outil de post synchro fait parler de lui cette semaine. Il s’agit de Lipdub AI. L’outil est en beta, il faut s’inscrire une waitlist et prendre un rdv dans le Calendly du Vice President Sales qui est booké jusqu’au mois de décembre. J’ai passé mon tour.
Concrètement, ça fonctionne mieux que lipsync de Runway, mais ça ressemble plus à une animatique de PS4 qu’à la dernière performance de Meryl Streep :
🔹Hailuoai now speaks english
Le site de génération vidéo IA text2video, gratuit, également connu sous le nom de Hailuoai Minimax, s’internationalise avec une interface en anglais. Fini les traducteurs et les prompts en chinois ! La rumeur parle d’un mode img2video “imminent”. S’il est est aussi performant que le txt2vid, ça risque de sentir très très bon... L’étau se ressert autour de Sora -es tu là?- qui est annoncé pour Novembre. Les quizz comparatifs entre modèles de Gilles s'annoncent challenging !
Et OpenAi n’aura plus qu’à sortir Sora 2 pour garder une avance qui semble fondre de semaine en semaine.
Je rappelle que Hailuoai est gratuit, vous n’avez donc plus aucune excuse :
🔹La guerre du lipsync est déclarée !
Kling propose une mise à jour des modèles 1 et 1.5 de Kling AI avec intégration de la synchronisation labiale. Les premiers résultats sont plutôt cohérents, surtout en anglais… Gilles a tout de même fait un comparatif entre Runway et Kling, en français s’il vous plait ! (Rappel : MASSIL.IA #2, c’est ce soir !)
🔹ChatGPT Canvas
OpenAI vient de dévoiler Canvas, une nouvelle fonctionnalité pour ChatGPT, peu après le DevDay. Contrairement à son homonyme, Canvas offre une fenêtre séparée pour travailler en collaboration avec l'IA. Elle propose des suggestions d'édition, des ajustements de longueur et de niveau de lecture, ainsi qu'une assistance pour la revue de code et la correction de bugs. Cette innovation transforme l'interaction avec ChatGPT en un véritable espace de travail collaboratif, offrant une nouvelle dimension dans l'utilisation de l'intelligence artificielle.
🔹Octobre rose by Ifonly
Après avoir mené un projet similaire à Londres l'année dernière, l'artiste Vincent Smadja, alias Ifonly, revient avec une nouvelle série d'œuvres générées à l'aide de Midjourney, Magnific AI, Firefly et Kling AI. Cette initiative s'inscrit dans le cadre d'Octobre Rose pour sensibiliser au cancer du sein. La bande sonore est un remix de Nightcall par Kavinsky, Angele et Phoenix.
“If only today’s awareness became tomorrow’s cure…”
🔹Hedra 2
Hedra sort un nouveau modèle appelé “Character-2”. Terminé les vidéos carrées, le modèle prend désormais en charge les formats grand écran et vertical. Hedra revendique également une amélioration de la qualité : plus de clarté, davantage d'expression, et une durée maximale des vidéos de 4 minutes.
En 896x512 pixels, on n’est pas encore en HD mais c’est un peu mieux qu’avant.
🔹 Et pendant que Gilles s’éclate
Vous vous souveniez de NotebookLM ? C’est l’un des gros buzz du moment sur le net. Vous fournissez n’importe quel type de source, et l’IA en fait un épisode de podcast ultra réaliste. On avait essayé avec GENERATIVE il y a 2 semaines.
Il n’en fallait pas plus aux editeurs d’avatars pour surfer la vague avec d’abord Synthesia, grand concurrent de HeyGen, qui met en scène une crise existentielle absurde entre 2 avatars Synthesia EXPRESS-1.
HeyGen a fait la même chose avec cette discussion philosophique troublante de réalisme :
🔹Heygen Caméléon
Heygen toujours propose une nouvelle fonctionnalité Avatar Looks qui permet de personnaliser à l'infini vos avatars. Vous pouvez désormais modifier arrière-plans, tenues, angles et positions pour des vidéos plus captivantes. Plus de 50 nouveaux avatars et 400 clips ont été ajoutés pour stimuler la créativité des utilisateurs.
🔹 La course à l’inférence
Côté image, Krea.ai nous annonce un Flux & Furious, 3 fois plus rapide pour 4 générations “de haute qualité” en seulement 4 secondes suite à leur intégration du modèle via Krea Flux.
Cette rapidité est rendue possible grâce au modèle Flux Schnell, dont les performances sont assez proches de Flux 1.0 mais en-deça de Flux Realism.

🔹Flux 1.1 Pro
Black Forest Labs a dévoilé Flux 1.1 Pro, une nouvelle version de son outil de génération d'images, permettant aux créateurs de produire des visuels six fois plus vite sans compromettre la qualité. Je l’ai essayé sur Freepik, et je lui préfère Flux Realism et Mystic V2 pour l’instant.
Vous pouvez l’essayer ici : https://flux1.ai/flux1-1 , sur Freepik ou sur Sezam.
🔹 La course toujours
De son côté, après le succès des camera motions, Luma Dream Machine v1.6 offre une génération vidéo “Hyperfast”, créant une vidéo de 120 images (5 secondes) en seulement 20 secondes avec une qualité totale grâce à une inférence 10 fois + rapide.
🔹36-15 my life
Lundi dernier j’étais à Lyon pour un rdv professionnel. J’en ai profité pour boire un café avec ma camarade Nathalie Dupuy, talentueuse D.A., experte Midjourney et créatrice du magazine “IALS” dont je vous recommande la lecture

🔹Un haircut à la Gaussienne
Des chercheurs ont mis au point une nouvelle méthode pour reproduire des cheveux avec un réalisme impressionnant en 3D, en combinant des mèches virtuelles et des formes mathématiques appelées gaussiennes. Cette technique permet de créer des coiffures détaillées à partir de simples vidéos avec des rendus capillaires ultra-précis, parfaits pour l'animation et les effets spéciaux dans les moteurs graphiques.
Le coin des outils en local :
Hugging face propose un outil de réglage assez fin sur les visages ou le corps, ce qui peut s’avérer être un excellent module complémentaire à Midjourney. De quoi garder le sourire malgré le raz de marée de news qui nous tombe dessus chaque semaine avec Gilles. Cadeau bonus, on vous met le lien hugging face en giveaway ici, enjoy les amis : https://huggingface.co/spaces/fffiloni/expression-editor
🔹IA, droits d’auteur et open source
Un tribunal d'Hambourg a tranché en faveur de LAION, association à but non lucratif qui créé et diffuse des modèles et des jeux de données d'IA en open source, pour entrainer des modèles d'apprentissage automatique capables notamment de générer des images.
Le contexte est une affaire de violation de droits d'auteur concernant l'utilisation de photos pour entraîner des modèles d'IA. Le photographe allemand Robert Kneschke avait intenté une action contre LAION pour avoir inclus ses images dans leur dataset sans son consentement. Le tribunal a estimé que LAION pouvait bénéficier de l'exception de fouille de données à des fins scientifiques, car leur dataset est non commercial. Reste à voir si le plaignant fera appel de cette décision.
🔹”C’est quoi ton background ? “
Utiliser Stable Diffusion 1.5 pour générer des arrière-plans avec un personnage créé séparément via la méthode vidéo-to-vidéo d’Animatediff, c’est la proposition de Deniz Rizikov. Une fois n’est pas coutume, tous les éléments générés ont été ensuite assemblés dans After Effects. On commence à voir de plus en plus de workflows autour des champs de profondeurs, notamment côté 3D. ici l’isolation du fond nous rappellent les “haikei tantou”, ces assistants en charge des backgrounds et arrière plans dans les animés et le manga. A suivre.
🔹ElevenReader passe la seconde !
ElevenReader, l’app d’Eleven Labs qui permet de “lire” des contenus à travers des voix incroyablement réalistes, fait peau neuve. L’application, disponible gratuitement, invite aussi les auteurs indépendants et les créateurs de contenu à publier directement sur la plateforme, leur offrant ainsi la possibilité de se connecter avec des auditeurs du monde entier.
🔹Déjà dans Minority report ?
L'évolution des outils d'interaction pour créer du contenu est en perpétuelle évolution. De nouveaux formats émergeront pour manipuler les histoires en temps réel comme l'illustre Kat ⊷ the Poet Engineer avec des interfaces de plus en plus créatives combinées à des gestuelles spécifique. La technologie redéfinit constamment notre manière de créer et de raconter des récits et cela ouvrira des perspectives inédites pour l'expression humaine. On vous laisse apprécier ici la beauté du geste :
Pour les geeks et les passionnés, voilà le tuto :
🔹 Un duo hybride
Vous trouviez que le nouveau mode vocal de chatGPT manquait de créativité ? Ce guitariste amateur a poussé chatGPT Voice dans ses retranchements pour en faire son choriste attitré. Un moment science fictionesque comme on les aime :
MASSIL.IA #2
Rappel à tous les sudistes et toutes celles et ceux qui aiment le soleil, MASSIL.IA revient ce soir ! toutes les infos ICI

Le projet IA de la semaine
L’année dernière, j’ai réalisé une pub TV pour la marque Tediber. J’ai même essayé de mettre de l’IA dedans, j’en parlais en détails ici.
La semaine dernière, Tediber me recontacte pour réaliser une série de visuels IA pour la Fashion Week à Paris. Leur idée est séduisante : une robe faite avec du duvet de couette, portée par un mannequin en plein catwalk.
Ils me donnent 3 éléments : un délai (hyper short), un brief et des photos de leur robe.
Je décide d’explorer 2 pistes différentes :
1 - reproduire leur robe avec un LoRA
2 - créer des visuels plus libres avec l’IA
Mission LoRA
J’uploade une trentaine de visuels de la robe portée sur plusieurs plateformes :
Fal.ai, Astria.ai, Replicate.com, Flair.ai et Everart.

Je lance ensuite les trainings.
Fal me fait un fail (qualité du jeu de mots)
Même chose sur Replicate. Des messages d’erreur dans les deux cas. Pas le temps ni l’envie de débugger.
Flair me propose quelque chose d’assez approximatif dans le rendu de la robe :

Sur Everart et Astria, c’est encore pire :

C’est alors que mon moment “Eurêka” survient.
Bah oui Jean-Kevin : il est où ton prompt ?
Contrairement aux LoRAs de visages où il n’est pas nécessaire de décrire le visage dans le prompt, ici il semble nécessaire ici de décrire la robe souhaitée (et avec les photos de laquelle on a pourtant entraîné le LoRA !)
Plutôt que de réinventer l’eau tiède, je choisis le raccourci GPT-Vision, et demande une description d’une photo d’origine à chatGPT :

Je balance le prompt précédé de la phrase : “Full body shot a model catwalking during fashion week”. Et là, ça change tout :

La robe est très fidèlement restituée.
En revanche, je dois me rendre à l’évidence : le LoRA a parfaitement “mémorisé” le visage de la jeune femme, qu’il reproduit avec précision, peu importe ce que je lui mets dans le prompt. Mais moi je veux avoir le choix du visage des modèles.
C’est alors que j’ai une idée : faire un nouvel entrainement, sans visage.

Je relance le training, je rédige un long prompt qui commence par : “Full body shot a tall top model catwalking during fashion week in a French Palace. She is wearing an unconventional outfit made from a white duvet and large pillows.” La suite est la description proposée par chatGPT. J’ obtiens un peu plus de diversité qu’avant en ce qui concerne les visages. Mais la posture reste très figée.

Je comprends alors que le problème vient de l’entrainement de mon LoRA. Il manque de variété. Une seule pose, la même posture, plusieurs angles.
Dans ce cas de figure, on dit que le LoRA fait de “l’overfitting”.
Ça veut dire que le LoRA va performer extrêmement bien sur la robe et la posture, qui sont sur-représentées dans le dataset d’entrainement. A l’inverse, il va avoir beaucoup de difficultés à proposer de la diversité. Parfaitement logique, après coup.
Alors, qu’est-ce qu’on fait ?
Pas le temps de bricoler un nouveau dataset avec la robe exacte. La 2e piste que je privilégie, c’est la création from scratch, à partir des éléments du brief : un catwalk en robe Tediber pendant la Fashion Week à Paris.
Let’s go Bro (oui, je suis mon propre Bro quand je me parle à moi même en travaillant)
C’est le moment où je dois te faire une confidence : Depuis la sortie de Flux, l’amour fou que j’éprouvais pour Midjourney commence à s’éroder.
Midjourney c’est génial pour l’hyper créativité. Mais c’est plus compliqué pour représenter des trucs précis.
Midjourney, my ex-love
Mais parce que je l’aime toujours, je commence par le prompter avant les autres.
Je démarre en douceur par un “describe”. Je ne suis pas fan de la fonction describe, je trouve que ça tombe presque toujours à côté. Ça fait davantage “vaguement inspiré de” que “fais la même chose stp MJ”.
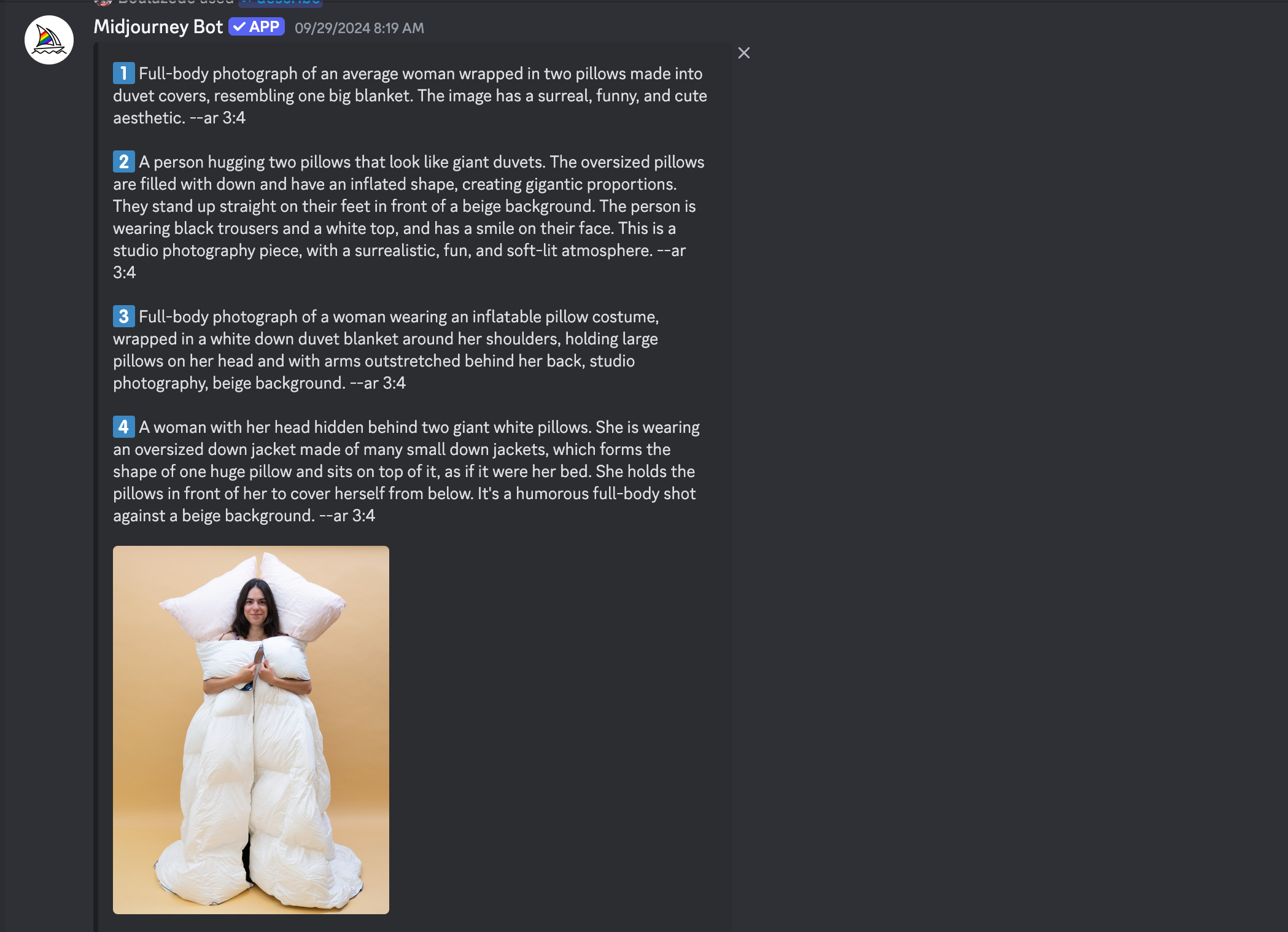
Vous voyez ce que je veux dire ?

“Okay” je me dis, je vais lui mettre la photo de la robe en image de reference, je termine par un —iw 2.0 (influence maximale de l’image de référence sur l’output) et un —sref de l’image de référence :

Flux Realism
En parallèle à Midjourney, je lance les même prompts sur Flux Realism, via Freepik.
Deux salles, deux ambiances.

Dès les premiers prompts, on est déjà plus proche de l’intention du brief. Je sens que je vais gagner du temps. Je commence à mitrailler Flux, en ajustant graduellement mon prompt au fil des générations. Je vais même jusqu’à faire décrire à chatGPT une photo catalogue de couette Tediber, pour obtenir leurs patterns carrés si caractéristiques de la marque :

Je conserve les termes descriptifs, les intègre dans le prompt et je repars à l’assaut du bouton “Create”. J’ai généré environ 400 images en tout, dont quelques-unes avec Mystic v2 et Nova-2 Ultra de Sezam.

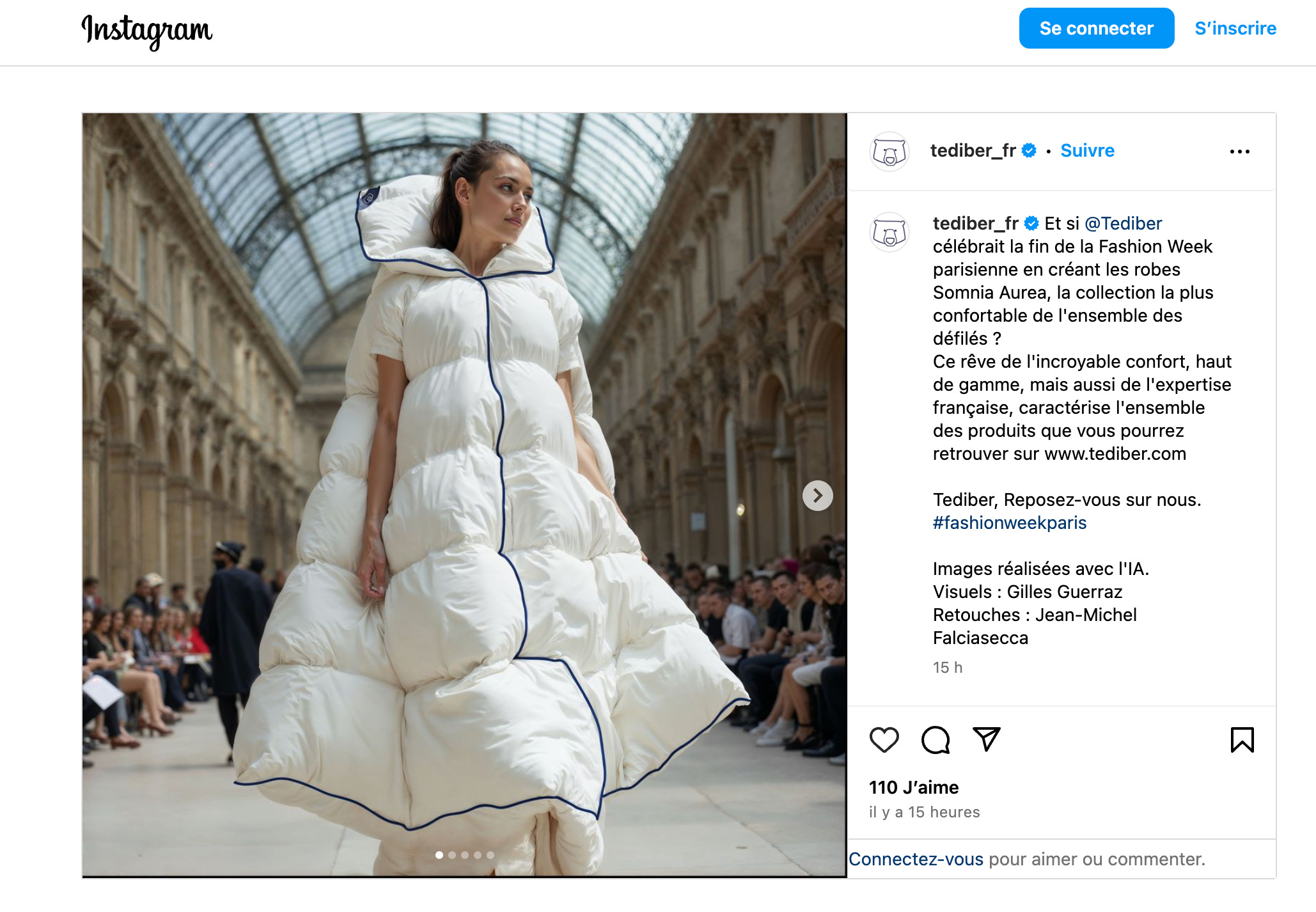
En visio avec la Directrice Artistique de Tediber, on shortliste 10 images. Puis elle en sélectionne 4, que j’envoie au magicien Jean-Michel Falsiasecca, qui incruste les logos et le liseret bleu de la marque.
J’étalonne le tout dans Adobe Camera Raw (j’ai testé le Relight de Magnific AI, mais je préfère le contrôle manuel fin et précis de Camera Raw). Le résultat est validé et publié sur le compte Instagram de Tediber.
N’hésitez pas à aller liker le résultat final, ça leur fera plaisir et à moi aussi !
La vidéo de la semaine
La pépite de la semaine nous vient de Jean-Baptiste Lefournier, un camarade réalisateur plutôt doué avec les outils d’IA générative… et avec l’humour.
Cette édition est terminée, merci de l’avoir lue jusqu’ici ! Si elle vous a plu, vous pouvez la partager en cliquant juste ici :
Vous pouvez également me suivre sur LinkedIn et activer la cloche 🔔, je poste régulièrement sur l’intelligence artificielle générative. Vous pouvez également me contacter pour toute proposition de création, intervention, conférence, projet, formation liée à l’intelligence artificielle générative.
Et n’oubliez pas de vous abonner pour ne rien rater des prochaines éditions 👇
Tellement intéressant, on veut plus de contenu comme celui de la robe Tediber !