


Veo 3 to the Next level !


Salut les surchargés, et bienvenue dans cette 118e édition de GENERATIVE, la newsletter obèse malgré elle.
Cette semaine encore, les sphères de l’IA générative étaient agitées (et on ne vous parle même pas des robots qui réalisent des interventions chirurgicales sans aide humaine ou des chiens robots chinois qui battent des records de vitesse (true stories)).
On a beau faire le focus sur la génération d’images et de vidéos uniquement, ça dépasse comme chaque semaine.
Soyez résilients, les vacances arrivent bientôt. Dans l’attente, asseyez vous et prenez une bonne inspiration, c’est parti !
Si ce n'est pas déjà fait, tu peux aussi :
Découvrir mes formations IA pour les créateurs, 100% finançables par le CPF. Les inscriptions se font ici.
Former tes équipes à l'IA générative grâce à nos formations entreprise finançables par ton OPCO
Nous contacter directement pour discuter de ton projet IA générative
Me suivre sur LinkedIn, YouTube ou TikTok pour ne rien rater.
Et c'est parti ! 🚀

🔹 Veo 3 : image-to-video avec audio intégré
Google DeepMind ajoute la fonction Image-to-Video avec audio intégré à VEO3. On peut désormais générer une vidéo complète à partir d’une seule image et y inclure des personnages cohérents, des produits stables, un style modifiable, une synchronisation labiale et des effets sonores. Cette mise à jour améliore le contrôle créatif : les visages sont identiques d’un plan à l’autre et le rendu global est cohérent.
Voici quelques démos qui ont retenu notre attention à la rédaction :
🔹 Marey par Moonvalley : IA vidéo générative éthique et contrôlable
Moonvalley dont on vous parlait déjà en Mars dernier, propose un accès public à Marey, son modèle vidéo génératif conçu avec des cinéastes et entraîné exclusivement sur des vidéos HD sous licence.
L’outil, déjà disponible via une interface web ou sur ComfyUI (et prochainement par intégration API), permet de générer des vidéos de 5 secondes en 1080p avec la promesse d’un contrôle précis sur la pose, le mouvement, l’angle de caméra et la trajectoire. Dans les faits, c’est parfois un peu plus compliqué.
La démo Moonvalley :
Le premier test de Gilles : C’est pas mal. Pas ouf mais pas mal.
Son principal atout réside dans l’utilisation de contenus sous licence, permettant une exploitation commerciale sans risque juridique.
Mais il reste encore des progrès à faire : depuis la sortie de Marey, plusieurs utilisateurs ont signalé quelques problèmes techniques : générations échouées, fichiers corrompus, déconnexions, et crédits non remboursés en cas d’erreur.
Et la durée limitée à 5 secondes et le coût par génération peuvent aussi freiner les expérimentations… Il faut vite passer à la caisse avec des tarifs plutôt élevés : 14,99 $ (100 crédits), 34,99 $ (250 crédits) et 149,99 $ (1 000 crédits).
Une démo de Juha Pönkänen :
Une autre de Ed Ulbrich :
Celle de Chris Fryant :
Et enfin ce test de Brad T. :
🔹 MiniMax 02 : unlimited chez Freepik
Après un petit effet teasing ce mercredi, Freepik, qui affirme ne “pas suivre les règles”, offre le modèle vidéo MiniMax 02 en accès illimité du 10 au 17 juillet à tous ses abonnés Premium+ et Pro !
Les utilisateurs de ces plans peuvent donc générer des vidéos de 6 secondes en 768p, sans limite. Et Freepik annonce déjà de nouvelles fonctionnalités qui seront ajoutées chaque semaine, dont notamment des partenariats avec d’autres modèles vidéo pour continuer à étendre leur Suite.
On a testé : on s’accorde à trouver la qualité moins bonne via l’PAi de Freepik que sur le site de Hailuo… Et vous ?
🔹 Flora & Veo3 + audio
Et le premier à activer la nouvelle fonctionnalité pour générer un visuel, avec synchronisation labiale et bruitages à partir d’une seule image avec VEO 3, c’est Flora, très discrètement ce jeudi soir sur sa plateforme nodale.
Caro, qui est creative partner chez eux, a décidé de faire le point de la Rédaction sur ce début d’année 2025 avec du text-to-video + audio à l’issue de cette année intensive, ambiance Vivatech. J’en perds mes mots… et le latin de mes sous-titres !
🔹 Freepik AI x ElevenLabs
Freepik permet désormais de générer des voix à partir de texte dans plus de 30 langues et avec plusieurs accents disponibles. La fonctionnalité repose sur la technologie d’ElevenLabs (of course, puisqu’ils souhaitent devenir l’acteur SON incontournable comme on vous le disait dans l’édition de mi-Juin) et s’intègre à leur Suite Ai pour produire des contenus audio directement depuis la plateforme, sans passer par un autre outil.
🔹 LTX Studio & ses 3 LoRA open source
LTX Studio propose Veo3 Fast depuis hier et publie 3 modules LoRA pour affiner son modèle vidéo IA open source :
- le module Pose LoRA permet de reproduire des mouvements précis en extrayant les squelettes corporels à partir de vidéos de référence ;
- celui de Depth LoRA améliore la cohérence spatiale en maintenant une structure 3D stable dans les scènes générées ;
- Enfin, le Canny LoRA capte les bords fins pour produire un rendu plus net et stylisé.
🔹 Vidu AI & la fonction “Video Reference”
Vidu permet désormais de générer des vidéos à partir de références visuelles en important des images pour conserver la cohérence des personnages, décors ou objets, quel que soit l’angle de vue. Un outil dans la lignée des Runway Reference et Kling Multi-Elements.
🔹 Kling est meilleur en vidéo qu’en photo
Kling sort Kolors 2.0, nouvelle version de son générateur d’images. Verdict : Bienvenue en janvier 2024 :

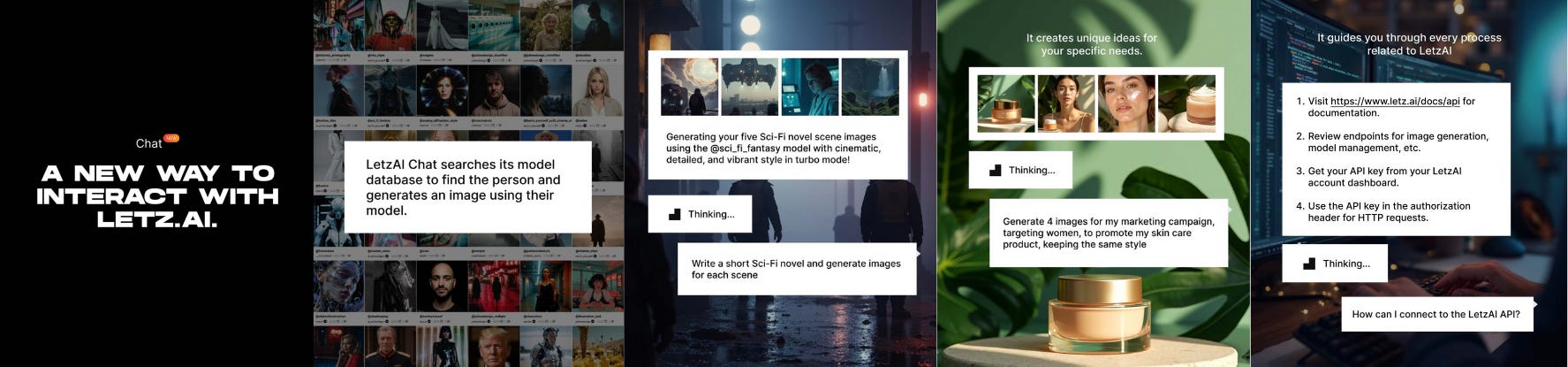
🔹 LetzAI & son Chat
LetzAI lance un assistant conversationnel capable de générer des images à partir de simples instructions en langage naturel, en un mot son chat. Il est possible de demander une séance photo virtuelle, des variations de style ou une série complète d’images. Le chat sélectionne les bons modèles, rédige les prompts et lance la génération en quelques secondes. L’outil prend aussi en charge l’édition de style, l’upscaling et l’assistance sur la plateforme. Disponible en accès anticipé pour les abonnés Fun, Pro et Enterprise.
🔹 Higgsfield Soul ID : création d’avatars IA à partir de vos photos
Higgsfield propose de nouveaux presets de Soul cette semaine, mais surtout Soul ID, son outil maison de génération de LoRas. Avec 20 à 70 photos sous différents angles, l’IA pourra recréer le personnage et le décliner dans plus de 60 styles visuels. (attention quand même à fournir un échantillon avec des images qualitatives si vous ne voulez pas être surpris à l’arrivée). Toujours très orienté contenus UGC et réseaux sociaux, les presets des styles SOUL sont très forts et laisseront assez peu de créativité aux générations.
🔹 Veo 3 text-to-video chez Fal.AI et Seelab.AI
Veo 3 text-to-video est désormais disponible sur Seelab.ai, l’image-to-video ne devrait pas tarder tout comme le Veo3 image-to-video + audio.
Petit aperçu avec cette vidéo signée Denis Larzillière.
La version Fast de Veo 3 en text-to-video est également accessible sur Fal.ai à un tarif fixé à 0,75 $ pour 5 secondes de vidéo de 40 centimes par seconde de vidéo ! (le tarif a été revu à la hausse peu de temps après la dispo du modèle). Pour tester, c’est par ici.
🔹 Dreamina Video 3.0 Pro désormais disponible en Europe
Le modèle vidéo avancé de ByteDance, Dreamina Video 3.0 Pro, est maintenant accessible aux utilisateurs européens via CapCut. Alimenté par Seedance 1.0, il propose un bon niveau de qualité.
Contre-partie à ne pas négliger, depuis cette semaine Capcut se réserve le droit de réutiliser tous vos rushes téléchargés dans l’application.
🔹 Veo 3 image-2-video
Veo 3 en image-to-video est également disponible depuis cette semaine dans Krea :
Mais aussi dans Weavy AI :
🔹 Imago VitA-i
Imago VitA-i est un workflow ComfyUI pour intégrer des personnages IA dans des scènes 3D ou photographiques avec une bonne cohérence visuelle. Quatre modes sont disponibles : génération par prompt, insertion automatique, placement guidé ou fusion avec une image existante. L’outil ajustera automatiquement lumière et couleurs selon le style ou l’heure choisie et fonctionnera en local, sans API ni restrictions. “Prometteur” comme diraient les LLM, mais aucun lien encore accessible pour le moment. A suivre donc !
🔹 Gaussian Memory : atelier IA & 3D dans Houdini
Un atelier en ligne de 3h est prévu le 17 août 2025 pour apprendre à intégrer des scènes IA reconstruites via Gaussian Splatting dans Houdini FX. L’objectif est de transformer ces données en architectures 3D narratives et visuelles. Ouvert aux débutants, le cours combine démonstrations et pratique sur les outils Houdini (Apprentice), Luma AI & MidJourney. Plus d’infos par ici.
🔹 Cartoon Hero 1.0 : génération de vidéos animées en style anime
Framer qui proposait déjà des cours en ligne pour créer des animés, lance Cartoon Hero 1.0, un outil IA pour créer des vidéos de 15 secondes dans ce même style. Cela vous en coûtera 10 à 60 minutes de génération et jusqu’à 5 $. L’outil, qui vise les contenus courts pour TikTok, YouTube ou Instagram, n’est pas encore disponible mais il est possible de s’inscrire sur Waitlist.
🔹 Dream Lab LA : un studio entre IA et narration cinématographique
Luma Labs présente Dream Lab LA, leur nouveau studio basé à Los Angeles, dirigé par Verena Puhm et Jon Finger. Cet espace de collaboration a pour ambition d’explorer de nouvelles formes de narration avec une approche centrée sur les artistes, loin des simples plateformes techniques. C’est beau ! On attend de voir !

🔹 L’open source de la semaine : Invoke 6.0
Invoke 6.0 propose une interface qui permet de pratiquer inpainting, outpainting et composition par calques juste avec la souris. Il permet aussi de gérer les modèles, de générer des images en lot et d’exporter en PSD avec calques. Compatible à Kontext Dev et aux plateformes nodales, l’outil fonctionne aussi en local et se positionne comme une alternative gratuite à Photoshop. Voici une démo de Darren Horrocks :
🔹 Breaking News ! YouTube stoppe la monétisation des contenus IA sans valeur
À partir du 15 juillet 2025, YouTube ne rémunérera plus les vidéos générées par IA sans contribution humaine claire, comme les voix off automatisées ou les diaporamas sans commentaire. L’IA reste autorisée si elle sert à créer un contenu original, avec analyse ou créativité. Cette décision vise à limiter la diffusion massive de vidéos générées automatiquement, devenues très visibles sur la plateforme ces derniers mois.


🔹 Titre
La vidéo de la semaine c’est cette fausse pub très inspirée pour la marque d’eau pétillante américaine “Liquid Death”. Conçue par le duo de réalisateurs Too Short For Modeling avec Amir Ariely, ancien directeur créatif mondial chez Google, cette vidéo a été réalisée avec Veo 3.
Ce qui est intéressant ici, c’est comment la créativité et la qualité de l’écriture prennent le pas sur la technique.
Cette édition est terminée, merci de l’avoir lue jusqu’ici ! Si elle vous a plu, vous pouvez la partager en cliquant juste ici :
Vous pouvez également me suivre sur LinkedIn et activer la cloche 🔔, je poste régulièrement sur l’intelligence artificielle générative. Vous pouvez également me contacter pour toute proposition de création, intervention, conférence, projet, formation liée à l’intelligence artificielle générative.
Et n’oubliez pas de vous abonner pour ne rien rater des prochaines éditions 👇