
Let's go 2026 !


Salut les rescapés de 2025, bienvenue dans cette première édition de l’année 2026 !
On n’est que le 9 janvier mais il s’est déjà passé plein de trucs, tellement de trucs, trop de trucs, comme on pouvait s’y attendre.
On vous raconte tout, let’s go !

Si tu es nouveau par ici, je suis Gilles Guerraz, réalisateur publicitaire devenu expert en outils créatifs GEN AI. Avec Caroline Thireau (AI Creative Technologist), nous te proposons une plongée hebdomadaire dans la marmite bouillonnante de l’actualité de l’IA générative !
Si on t’a transféré cette lettre, abonne-toi en un clic ici.
Ma prochaine session de formation CPF aura lieu à Paris les 22 et 23 janvier prochains !
Si tu es salarié.e ou indépendant.e, et que tu souhaites monter en compétence sur la génération d’images et de vidéo, tu es le/la bienvenue.e !
La session est 100% finançable par le CPF. Les inscriptions se font ici.
Cette semaine, nous mettons à l’honneur un confrère ! Il s’agit de la newsletter GPToast qui propose des news quotidiennes et généralistes sur l’IA, parfaitement complémentaire à GENERATIVE. Vous pouvez vous y abonner en cliquant sur le bouton “s’abonner” ci-dessous :

Si ce n'est pas déjà fait, tu peux aussi :
Découvrir mes formations IA pour les créateurs, 100% finançables par le CPF. Les inscriptions se font ici.
Former tes équipes à l'IA générative grâce à nos formations entreprise finançables par ton OPCO
Nous contacter directement pour discuter de ton projet IA générative
Me suivre sur LinkedIn, YouTube ou TikTok pour ne rien rater.
Et c'est parti ! 🚀

🔹 Lightricks LTX V2
L’outil phare de cette semaine nous vient de Lightricks. LTX-V2 est un nouveau modèle de génération de vidéo qui se distingue par ses caractéristiques.
Il est possible personnaliser le modèles avec ses propres données et donc avec ses LoRas. Le modèle s’adapte puisqu’il garde la structure, reproduit un plan et analyse précisément l’impact d’une modification de prompt. Cela fonctionne avec les LoRas de style de la même façon que dans l’exemple ici :
LTX-2 est optimisé pour les cartes graphiques grand public NVIDIA RTX standard.
Les formats standards (16:9, 9:16, 4:3) ou sur mesure sont possibles. Utile pour l’édition ou des formats réseaux sociaux. Les générations s’effectuent localement, sans compression serveur ni limitation par clip. Un pas de plus dans l’editing directement intégré aux outils IA ?
LTX V2, c’est aussi une résolution annoncée en 4K, selon la mémoire GPU disponible, mais aussi les VRAM, durée des clips et réglages internes. Le frame rate (nombre d’images par seconde) est lui entièrement paramétrable, ce qui permet d’adapter le rendu à une animation saccadée, un test de mouvement ou une intégration en montage classique. Ici un exemple en 4K 50 fps : on vous laisse apprécier le niveau d’upscale :
Autres exemples de fonctionnalités possibles dans Ltx :
- OpenPose Driven Motion : (une réponse direct à Kling Motion control ou Luma Modify)
Depth aware génération : (une technique bien utile en video -to-video pour conserver les contrastes et profondeurs de champs)
On vous partage aussi ici une démonstration de László Gaál que Gilles citait cette semaine en parlant de cette news :
Notre camarade Neb Sh du prompt Club, fidèle utilisateur de LTX, nous disait que les LoRas sous LTX1 fonctionnaient toujours sous LTX2. Son dernier post parle également des effets AMGERY qu’on vous laisse découvrir ici.
🔹 Higgsfield Cinema Studio v1.5
Au delà de ses campagnes média parfois douteuses, Higgsfield propose des outils de plus en plus spécifiques comme le Cinema Studio que Gilles avait passé au crible sur notre dernière édition 2025.
Leur version Cinema Studio se met à jour avec un contrôle de l’ouverture du diaphragme, appelée communément “l’ouverture”.
L’ouverture du diaphragme, Kesaco ?
Le diaphragme, c’est comme la pupille de ton œil : un trou qui s’agrandit ou se rétrécit pour laisser passer plus ou moins de lumière.
Ce qu’il faut retenir :
Plus le chiffre est petit (f/1.4), plus le trou est grand → beaucoup de lumière entre, et l’arrière-plan devient flou (c’est le fameux “bokeh”).
Plus le chiffre est grand (f/16), plus le trou est petit → moins de lumière, mais tout est net de l’avant à l’arrière (idéal pour les paysages).
Dans le monde réel, l’ouverture va généralement de F/1.2 ou F/1.4 jusqu’à F/16, avec de nombreux incréments : 2.0, 2.8, 4.0, 5.6, 8, etc…
Chez Higgsfield, on n’a que 3 options : 1.4, 4 et 11.
Je suis allé faire un tour virtuel dans les quartiers nord de Marseille pour tester ça :

L’outil étend aussi son vocabulaire caméra : boîtiers cinéma reconnus, choix d’optiques et mouvements prédéfinis, orientés mise en scène plutôt que simple génération. Caro se demande : “Liraient-ils GÉNÉRATIVE chez Higgsfield ? “
🔹 Et… Higgsfield Relight
Higgsfield lance également Relight, un outil de retouche d’éclairage avec estimation de profondeur qu’on retrouvera dans ses apps boostées au nano banana. Des préréglages (avant, arrière, côtés, dessus, dessous) et un contrôle directionnel sont proposés mais l’image est traitée comme une scène 3D, ce qui permet aussi d’ajuster la direction, l’intensité et la température de la lumière. L’outil vise surtout le portrait, le produit et des ambiances colorées.
Avis de Caro : les coloris de light manquent un peu de finesse et quelques soucis de latence se sont fait ressentir sur cette feature.
🔹 Et… Higgsfield AI Stylist
Une sorte de virtual-try-on clé en main avec des tenues à choisir en drag&drop, au détail ou en tenue complète. Une barbie IA qui devraient intéresser les départements comm des marques de prêt à porter.
Avis de Caro : A la rédac, on a testé pour vous et on perd un peu en consistance. On se demande aussi qui est le personal shopper chez eux quand même.
Alors, est-ce qu’on valide ces looks 2026 ?

Avis de Gilles : Merci Caro pour cette nouvelle garde robe d’exception. Je ne trouve pas les mots.
🔹 Dreamina : Multiframe
Dreamina fait évoluer Multiframe avec la possibilité d’uploader jusqu’à 20 images clés pour des vidéos longues. L’outil accepte des entrées image+vidéo ou vidéo+vidéo. Le timing est réglable de 0 à 8 secondes par segment, avec une précision de 0,5 s. Une édition locale image par image est possible via des zones verrouillées ou déverrouillées. La génération tient mieux compte des mouvements de caméra et des transitions entre plans.
Avis de Caro : On connaissait leur multiframe, mais l’intégration de l’option d’input en video-to-video est un vrai plus.
🔹 Krea Image : Entraînement LoRA pour Qwen-2512 et Z-Image
Krea intègre les modèles prometteurs Qwen-2512 et Z-Image, ce qui rend possible l’entraînement de LoRA pour ces deux modèles. Les LoRA peuvent ensuite être utilisées directement dans Krea Image comme d’habitude.
Avis de Caro : à l’heure de Nano Banana Pro (ou NBP pour les intimes), certains se demandent si les LoRas continuent à être pertinents pour les questions de consistance. Cela évite en tout cas l’editing. Reste à voir ce qui est le plus rentable. Ici la différence vient surtout du niveau de qualité d’image lié aux modèles.
🔹 Kling Image 01 update
Kling update son modèle de génération d’images ! On a testé, c’est vraiment pas mal !



🔹 Weavy routers
Weavy propose des petits outils fonctionnels pour vous faire gagner du temps dans l’organisation en nodal :
- des routers pour clarifier les schémas sans nodes dans tous les sens ;
- la possibilités de regrouper plusieurs nodes ensemble selon les étapes du workflow ;
- la personnalisation de ces groupes (couleurs, titres, tailles…)
Proposés suite aux retours utilisateurs, leurs équipes montrent une fois qu’ils sont à l’écoute de leur communautés.
Caro en parlait cette semaine dans son workflow Weavy.
🔹 Partenariat Runway & Adobe
Runway était déjà arrivé en tant que modèle tiers dans la suite Adobe Firefly. A présent, les 2 acteurs annoncent un partenariat pluriannuel et prévoient aussi de développer ensemble des capacités d’IA dédiées à des flux de travail professionnels. Le communiqué de presse “officiel” par ici parlent de fonctions exclusives aux applications Adobe.
Il paraît que l’union fait la force et il est vrai que ce sont surtout les modèles asiatiques qui se sont démarqué ces derniers temps. A suivre.
Avis de Caro : On se demande si ce partenariat permettra à Runway de se positionner comme un modèle “autorisé” par Adobe sans qu’il soit écarté de certains abonnements (je pense notamment aux étudiants ou encore aux corporate dont l’utilisation de modèles tiers est proscrite.)
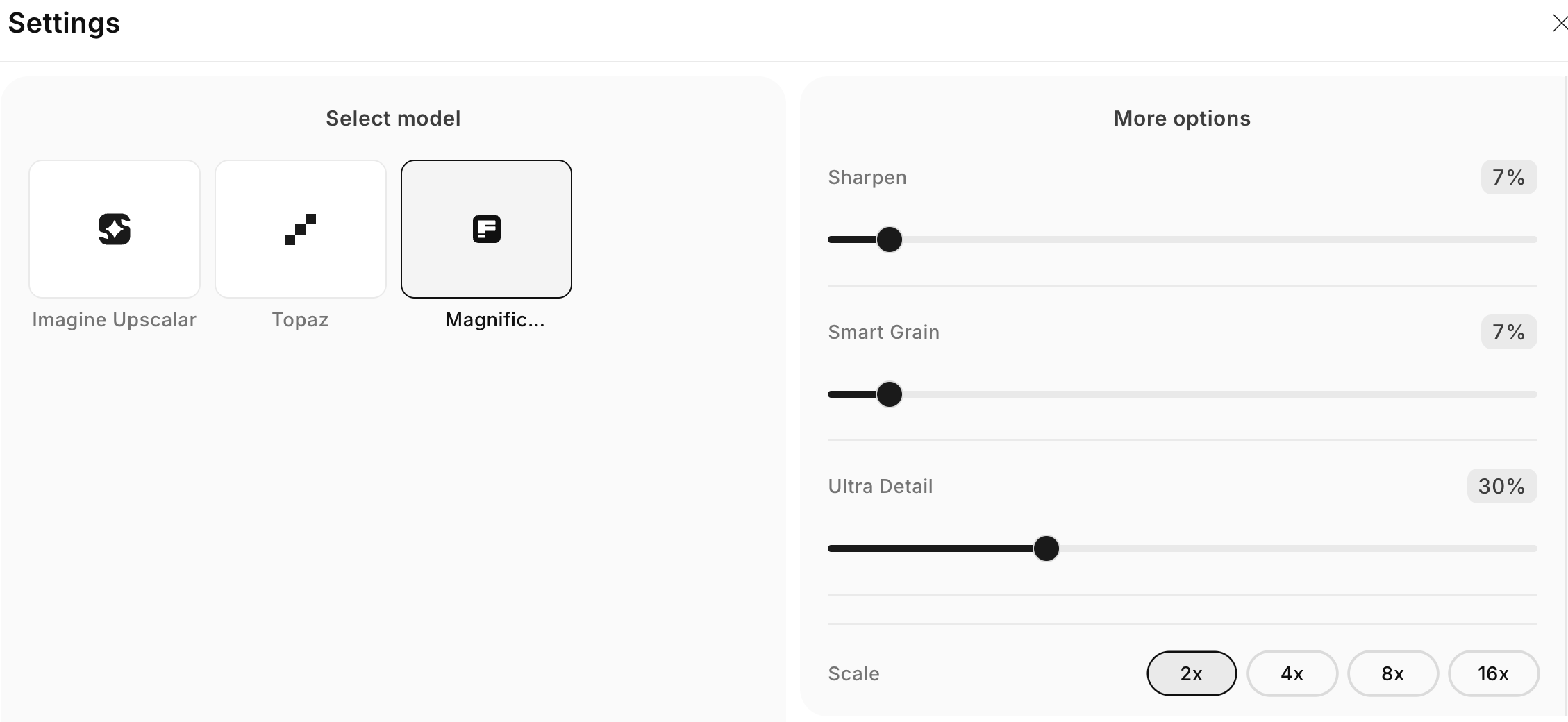
🔹 ImagineArt & Magnific AI
ImagineArt complète son offre d’upscaler avec Magnific AI en plus de Topaz et de leur modèle maison : de quoi agrandir les images jusqu’à 16 fois Quelques offres sont en cours sur leurs abonnements en ce moment.
🔹 Grok Imagine
Mise à jour majeur de Grok imagine : meilleure interprétation des prompts, amélioration de la génération audio, rendus visuels plus propres. Un modèle discret mais performant à suivre, si les questions éthiques ne vous rebutent pas trop.
Démo du camarade Pierrick Chevallier ici.
🔹 AI Motion Mimicry de Pixverse
Pixverse propose sa version de Modify de Luma, Qwen Replace ou de Kling Motion Control. Comme ses petits concurrents, l’outil prend une vidéo source et transfère les mouvements, expressions faciales et lip-sync vers une image fixe pour produire un avatar animé. Le flux est automatisé mais le résultat dépendra surtout de la qualité et du cadrage de la vidéo d’entrée.
🔶 CÔTÉ OPEN SOURCE
🔸 Stable Video
SVI est davantage un framework qu’un modèle, qui gère la continuité dans le temps. Il traite la vidéo comme une séquence unique et non comme une suite de clips. Chaque segment tient compte des précédents et peut corriger des incohérences en arrière. Le LoRA SVI sert à stabiliser identités, éclairage et matières mais pas le style.
La version 2 ajoute le “prompt streaming” pour mieux guider les actions et enchaînements. Plus de démo et de tests disponibles sous Github.
🔸UniVideo
UniVideo est un modèle vidéo open source développé par l’équipe Kling (Kuaishou) qui repose sur une architecture unifiée. En gros, il permet génération et édition in-context, stylisation, ajout/suppression d’éléments et enchaînement de plusieurs opérations en un seul prompt. Infos disponibles sur Github.
🔸 Comfy Ui LTX
LTX-2 dont on vous parlait en début d’édition a été également pris en charge nativement dans ComfyUI dès le lancement, ce qui renforce la contrôlabilité pour la génération de vidéo en open source grâce :
- au modèle de fondation audio/vidéo open source
- au contrôle vidéo-vidéo Canny, Depth & Pose
- aux générations pilotées par images clés
- à la mise à l’échelle native et à l’amélioration des prompts

🔹 L’assurance d’une spec ad à l’allemande
La pépite de la semaine nous vient de Christian Maria Brandes avec cette (fausse) publicité qui vise un réalisme allemand précis : visages, vêtements, architecture, mobilier, banlieues et voitures. La cohérence colorimétrique repose sur des prompts JSON et un étalonnage via DaVinci Color Warper. Les performances des personnages progressent grâce Act Two de runway et, surtout, motion control de Kling. La majorité du film est produite dans Higgsfield AI Cinema Studio, notamment pour le choix des caméras.
🔹 La blague de la semaine
Merci au camarade Emmanuel Vivier pour le partage de cette video humoristique qui nous rappelle que concevoir une vidéo IA précise reste complexe et parfois imprévisible malgré les évolutions que nous vous partageons ici chaque semaine.

 Tiktok failed to load.
Tiktok failed to load.Enable 3rd party cookies or use another browser
Cette édition est terminée, merci de l’avoir lue jusqu’ici ! Si elle vous a plu, vous pouvez la partager en cliquant juste ici :
Vous pouvez également me suivre sur LinkedIn (Caroline est par ici) et activer la cloche 🔔, je poste régulièrement sur l’intelligence artificielle générative. Vous pouvez également me contacter pour toute proposition de création, intervention, conférence, projet, formation liée à l’intelligence artificielle générative.
Et n’oubliez pas de vous abonner pour ne rien rater des prochaines éditionsons 👇