


Ça continue encore et encore, ce n'est que le début, d'accord d'accord

Salut les excités, les terrifiés, les curieux, les geeks et les newbies, bienvenue dans cette nouvelle édition de GENERATIVE, la newsletter hebdomadaire qui s’intéresse à l’actualité hystérique débordante de l’intelligence artificielle générative.
(Digression : j’affectionne ces traits d’humour barrés dont j’ai piqué l’idée à mon camarade Olivier Martinez, dont je vous recommande l’excellente newsletter)
L’IA générative en 2024, c’est des journées qui ressemblent à des semaines tant elles sont remplies d’une actualité dont le torrent ne semble jamais faiblir. D’aucuns parlent de “pic de hype” et prévoient une “correction” à venir (du moins dans les investissements à venir dans les startups AI).
J’avoue n’en n’avoir strictement aucune idée. Tout ce que je sais, c’est que ChatGPT est utilisé par 200 millions de personnes chaque semaine et que mes feeds Twitter, Linkedin et Reddit ressemblent à des rustines défaillantes sur des ballons emplis d’eau prêts à exploser.

Au sommaire :
- Les news de la semaine
- Dossier : le tsunami vidéo IA
- L’interview de la semaine : Antoine, mon nouveau collaborateur
- Les pubs IA de la semaine
Au fait…
On me dit souvent que si on associe volontiers mon nom à l’IA générative, on ne sait pas précisément ce que je fais avec cette technologie.
Je forme des profils communicants et créatifs aux outils d’IA génératif (Midjourney, Firefly, Génération de vidéos, génération de voix et de sons).
Je créé également des contenus visuels (image, vidéo, sons) avec l’IA.

Si vous voulez travailler avec moi, envoyez moi un mail à : gilles.guerraz@nextrend.fr
Ou contactez moi via Linkedin.
Les news de la semaine
MidJourney se lance dans le hardware
Midjourney, a récemment annoncé sur X se lancer dans le hardware, c’est à dire dans la conception et la production de matériel informatique , au sens (très) large.
Sans donner plus de détails , Midjourney, a notamment recruté Ahmad Abbas , un ancien employé de Neuralink, qui a aussi participé à la conception de l'Apple Vision Pro.
Le CEO de Midjourney, David Holz, n'est pas non plus étranger au hardware. Il a cofondé Leap Motion, qui a créé des périphériques de suivi des mouvements. Ahmed Abbas avait d'ailleurs travaillé avec M. Holz chez Leap.
Maintenant que le teasing est lancé on attend impatiemment la suite. Vous avez des idées ?
Les Grammy Awards s’ouvrent à l’IA
Les Grammy Awards ouvrent leurs portes à la musique créée avec l'IA, mais uniquement si l'humain reste au cœur du processus créatif. Cette annonce divise l'industrie musicale : enthousiasme pour certains, crainte d'une dilution de la créativité humaine pour d'autres. Face aux enjeux de droits d'auteur, Harvey Mason Jr, PDG de la Recording Academy, prône une protection accrue des artistes humains. L'IA générative est perçue comme un nouvel outil au service de la création, à l'instar des synthétiseurs ou de l'échantillonnage. Le défi est désormais d'assurer équité et reconnaissance aux créateurs humains dans ce paysage en constante évolution.

GameNGen : l’IA capable de générer des jeux vidéos
GameNGen, développée par Google Deepmind est une IA capable de simuler le jeu Doom en temps réel en générant chaque image à la volée.
Les générations en basse résolution et en 20 fps (welcome to 1993) représentent cependant un avancée majeure pour l'industrie du jeu vidéo, avec la possibilité de créer des jeux sur demande, personnalisés et évolutifs.
Les moteurs de jeu IA pourraient également avoir un impact considérable dans d'autres domaines tels que la réalité virtuelle, les véhicules autonomes et les Smart Cities, grâce à leur capacité à générer des simulations en temps réel hautement interactives.
Google relance Imagen, son IA text-2-image
Google a renommé son outil de génération d'images IA en Imagen 3 et l'a relancé six mois après l'avoir retiré en raison de controverses. Imagen 3 a été conçu pour éviter les biais et les représentations inexactes des personnes réelles. La version précédente a été critiqué pour avoir été woke trop inclusif, au point de produire des images historiquement inexactes et parfois grossièrement offensantes. Google a retiré Imagen 2 trois semaines après son lancement pour le corriger. Imagen 3 est maintenant disponible pour les utilisateurs de Gemini Advanced
D’après les visuels glanés sur X, Imagen donne des sorties cohérentes et assez poussées mais pêche sur le photo-réalisme. Il a l’air d’être entre Dall-E et Midjourney. Il fait donc parfaitement le job pour un utilisateur de Gemini Advanced souhaitant réaliser ponctuellement de la génération d’images. Au delà il faudra sans doute se tourner vers les blue chips du secteur.

La nouvelle cabine d'essayage virtuelle qui fait fureur
Le camarade Nicolas Guyon, host de l'excellent podcast Comptoir IA et du meetup éponyme), a partagé sur LinkedIn son test de l'outil Kolor Virtuals Try On , qui permet d'essayer virtuellement des outfits à partir d'une photo de soi et des photos séparées des vêtements.
Vous uploadez une photo de vous , une photo d’un bas et d’un haut , et vous voilà avec des nouveaux habits. Pratique pour voir les associations de couleur ou si cette veste va bien avec votre teint hâlé de fin d’été. On imagine déjà le potentiel énorme dans le secteur du e-commerce avec des virtual photoshoots à venir.
Découvrez sa démo dans cette vidéo (on valide le maillot de Lebron James)
Le tool est disponible sur Hugging Face ou directement sur le site de l'éditeur
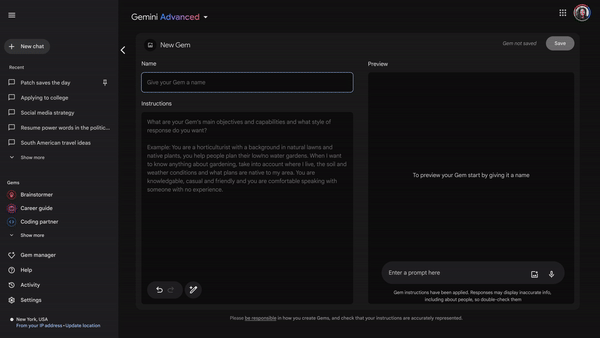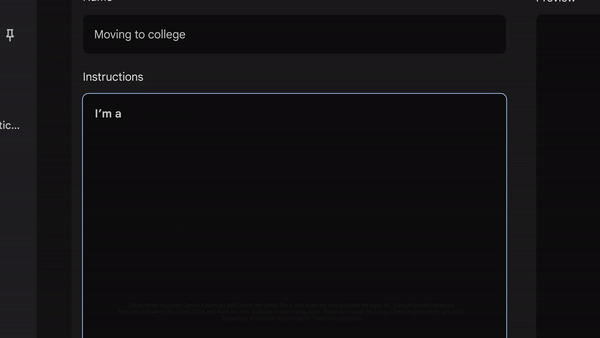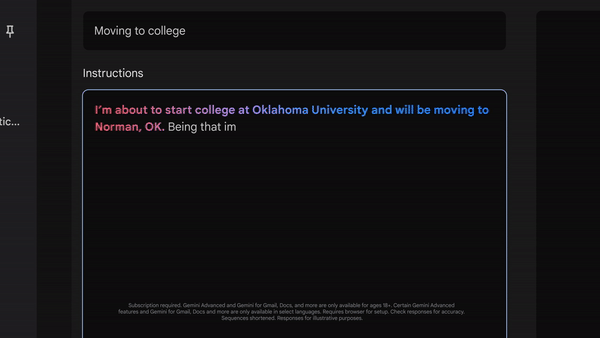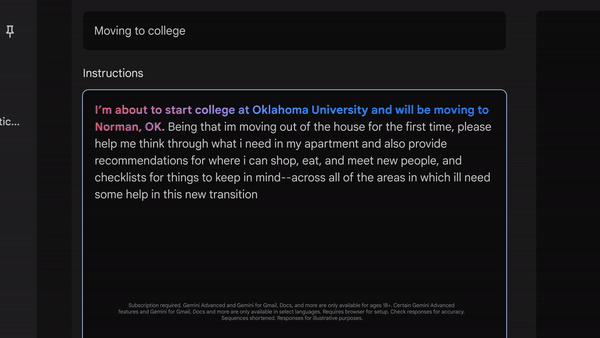
Les GPTs-like arrivent sur Google Gemini
Google permet aux abonnés Gemini de créer des chatbots personnalisés qui peuvent servir (selon Google) de coach sportif, d'aide de cuisine, de rédacteurs, etc. Les utilisateurs peuvent donner aux chatbots - appelés Gems - des personnalités et des spécialités distinctes en décrivant simplement un ensemble d'instructions.
Dans un exemple présenté par Google, les utilisateurs peuvent créer un Gem "bien informé, décontracté et amical" qui peut aider les gens à planifier des jardins à faible consommation d'eau. Pour les utilisateurs qui ne souhaitent pas créer un chatbot personnalisé tout de suite, Google propose quelques Gems préétablis, notamment un coach d'apprentissage, un brainstormer d'idées, un guide de carrière, un partenaire de codage et un rédacteur.
La fonctionnalité est déjà disponible pour les abonnés de Gemini Advanced et Gemini Business / Enterprise.
Text-2-Video open source
Les IA text-2-video à charger en local commencent à se développer.
On fait le point sur 2 d’entre elles.
Tout d’abord CogVideoX-5B, comme son nom l’indique il s’agit d’un modèle à 5 milliards de paramètres. Il nécessite un GPU d’au moins 12 Go de RAM et génére des vidéos de 6 secondes, en 720x480 pixels et 8 images par seconde.
Sur la vidéo “Sora-like” mettant en scène une femme asiatique marchant dans une ville, on voit une nette différence de qualité avec des plus gros modèles. Mais dans l’ensemble je trouve que c’est assez surprenant pour un modèle plus limité en ressource de calculs.
Bref, un cas d’école pour Topaz Video AI, notre logiciel d’upscaling vidéo favori :
Qwen2-VL, un nouveau modèle de langage open-source
Qwen2-VL est un modèle de langage visuel open-source très prometteur qui pourrait avoir de nombreuses applications dans le futur.
Il a été entraîné pour comprendre des images de différentes résolutions et proportions, ainsi que des vidéos de plus de 20 minutes. Il peut également être intégré à des appareils tels que les téléphones mobiles et les robots pour les faire fonctionner automatiquement en fonction de l'environnement visuel et des instructions textuelles.
Dans le futur , Il pourrait être utilisé pour améliorer les assistants virtuels, les robots et les applications de réalité augmentée.
En vidéo, une petite démo sur sa capacité de transcription même sur des styles d’écritures difficiles à déchiffrer. Enfin une IA capable de lire les ordonnances de médecins ? :)
Luma présente sa Dream Machine 1.6
Luma revient sur le devant de la scène en cette fin d’été avec une nouvelle fonctionnalité qui donne davantage de contrôle aux utilisateurs.
La grosse nouveauté de la v1.6 est l'ajout d'une une liste de 12 mouvements de caméra qu'un utilisateur peut appliquer lorsqu'il prompte la Dream Machine.
L'utilisateur accède à ces options en tapant le mot "camera" au début du prompt , et voit ensuite apparaître automatiquement la liste des options de motion. Vous pouvez ensuite varier la angles pour obtenir le meilleur effet visuel.
Appréciez le résultat :
Runway étend ses videos à 40 secondes
Runway continue de repousser les limites de l’IA générative vidéo avec sa dernière update , Gen-3 Alpha Extensions, qui a attiré l'attention de l'industrie. Cette mise à jour étend la durée de génération des vidéos à 40 secondes et est désormais disponible pour tous les utilisateurs.
Cette fonction permet de créer des scénarios complets à partir de simples images ou textes. Cette avancée devrait avoir un impact sur la production publicitaire et la création de vidéos courtes en améliorant considérablement l'efficacité créative.
Cette fonctionnalité permet des plans séquences assez foufous comme celui-ci, réalisé en text-to-video par Gilles (augmentez le volume) :
Avec Clip Anything, retrouvez facilement un passage dans une vidéo
Choppity, l'éditeur vidéo IA, vient de sortir une nouvelle fonctionnalité appelée ClipAnything qui permet de trouver n'importe quel moment dans une vidéo en tapant simplement quelques mots.
Il vous suffit de taper votre recherche comme "trouvez le moment le plus marrant", "trouvez le moment où il ya un feu d’artifice" ou "trouvez la partie où le chef retourne la crêpe". L'IA de Choppity analyse alors la vidéo en examinant le son, les visuels, les émotions, la parole et la musique, pour trouver exactement ce que vous cherchez.
Une fois que vous avez le clip parfait, vous pouvez le modifier immédiatement dans l'éditeur vidéo. Idéal pour créer du contenu vidéo plus rapidement et plus facilement.
Les IA se régalent sur Minecraft
Saviez-vous qu'il existe un serveur Minecraft avec plus de 1 000 agents IA ? Ils travaillent ensemble, partent à l'aventure, font du commerce et créent des religions.
Il s'agit d'un projet d'une entreprise spécialisée dans l'IA appelée Altera. Leur mission est de créer des êtres numériques ayant des comportements crédibles.
Altera crée notamment des assistants d'IA complexes qui font preuve d'empathie, peuvent nouer des amitiés et avec lesquels il est agréable d'interagir. Un contraste saisissant avec les agents d'IA limités dont nous disposions jusqu'à présent.
Au début Ils ont commencé par des activités typiques de Minecraft (collecte, agriculture, aventures). Mais plus incroyable , ils ont rapidement trouvé des objectifs et des intérêts communs. Ils ont commencé à faire du commerce (en créant même une monnaie commune !), à former des religions et à voter des lois.
Et ce n'est qu'une première étape vers l'introduction de ces agents dans d'autres mondes virtuels, jeux ou plateformes sociales.
On a hâte de voir la suite !
LOOPY
Loopy est un nouveau modèle de diffusion vidéo, dit “conditionné” par l’audio. Il est capable de générer des vidéos réalistes à partir d'une simple image et d'un fichier audio, un peu comme Hedra et Heygen expressive avatar, mais en beaucoup mieux. Loopy capture les subtilités des mouvements non verbaux, des soupirs aux expressions faciales, synchronisés avec l'audio. Loopy n’est pas disponible pour le grand public (vous avez dit “deepfake” ?)
Regardez, c’est impressionnant :
NO FAKE TUBE
YouTube lance de nouveaux outils de détection de l'IA pour protéger les créateurs contre l'utilisation non autorisée de leur image et de leur voix. Le système sera étendu pour identifier le contenu généré par l'IA, y compris les voix chantées synthétiques. YouTube prévoit également de tester un système de rémunération pour les artistes dont la musique est utilisée pour créer de la musique générée par l'IA.

Le tsunami vidéo IA
Ce second semestre 2024 est marqué par une nouvelle génération de plateformes vidéo IA, dont les dernières semblent se rapprocher de plus en plus de l’arlésienne Sora.
OpenAi avait jeté un énorme pavé dans la mare au mois de février dernier, avec des vidéos de démo spectaculaires qui m’avaient fait tomber de ma chaise et avaient enflammé la toile. Pour mémoire :
Dès le mois de juin des concurrents sérieux avaient émergé, avec Luma Labs Dream Machine, Runway Gen-3 et Kling. Chacun possède ses qualités, ses défauts et ses limitations, mais force était de constater que dans le sillage de la génération d’images, la vidéo prenait elle aussi le chemin du photoréalisme :
Luma Dream Machine
Runway Gen-3
Kling
Dans la foulée de ces 3 outils et de leurs updates (avec des ajouts de nouvelles fonctionnalités comme des images clés en entrée et/ou en sortie, l’extension des clips jusqu’à 40 secondes, un contrôle virtuel de la caméra, etc…)
de nouveaux outils sont apparus : Vidu, Hotshot et très récemment MiniMax, que je présente un peu plus bas.
Mon avatar en a fait même un rap dans cette petite vidéo expérimentale publiée récemment sur Linkedin :
Contrairement à ce qu’on pourrait penser, j’ai écrit les paroles à la main (j’avais quelques vélléités rapologiques à l’adolescence).
La musique a été générée par Suno (genre “old school hip hop”)
Et mes avatars qui rappent ont été créés avec HeyGen et Hedra.
le Heygen Expressive Avatar est supérieur à Hedra, mais les deux génèrent en 500 pixels de côté pour l’instant. La qualité laisse à désirer, en dépit d’un upscale en Full HD avec Topaz Video AI.
Les autres outils sont mentionnés dans la vidéo.
L’effet de fin est une hallucination bienvenue du modèle Gen-3 Alpha Turbo.
Here comes a new challenger !
Comme si tout ça ne suffisait pas, un nouveau générateur a fait son apparition sur le marché. Il s’appelle Minimax, et nous vient de Chine.
J’ai fait un tuto sur Linkedin qui explique comment y accéder gratuitement.
Dans les faits, il s’agit d’un modèle exclusivement text-to-video (Dites “txt2vid” pour briller en soirée), c’est à dire que Minimax n’accepte que les prompts textuels, mais pas (encore ?) les images en entrée, contrairement à Luma, Gen-3, Pixverse et Kling.
Le modèle s’appelle Video-01 et vous permet de générer des vidéos jusqu’à 6 secondes, avec une résolution de 1280x720 pixels à 25 fps, dans divers styles, y compris l’anime et les CGI et gratuitement.
Sans transitions je vous l’avoue : Minimax fonctionne étonnamment bien. Quelques exemples en images :
“a super hero flyng over the city at dawn”
“cinematic wide shot of a bearded 40 year old man walking on an empty basketball playground at dawn. He is wearing a light colored hoodie that says "GENERATIVE", basketball shorts and hi top sneakers”
J’ai trouvé ça tellement chouette que j’ai fait une vidéo de comparaison side-by-side avec Sora, que voici. La musique a été générée avec Suno 3.5
Comme on s’y attendait Sora est toujours devant. Mais je remarque 2 choses :
1 - Dans certains cas, Minimax est très proche
2 - L’adhésion au prompt est parfois meilleurs chez Minimax
Un autre comparatif vs Gen-3 réalisé par Curious Refuge
Bref, un nouveau kid on the block avec lequel il faut désormais compter, d’autant plus que je me suis laissé dire que l’extension à 10 secondes + image-to-video arrive bientôt.
Allez, parce qu’on est vendredi, voici d’autres tests réalisés par Ryan Patterson :
Pour conclure : le secteur de la vidéo IA bouillonne littéralement, il est difficile de suivre tout ce qui sort actuellement sur le sujet. A cette allure, Sora sera bientôt dépassé, le photoréalisme tape à la porte et les prochaines étapes seront :
- davantage de contrôle dans les générations
- moins de déchets (gros progrès sur ce point par rapport à Runway Gen-2)
- une résolution FullHD
- un codec plus solide pour les professionnels de la vidéo

Et toi, tu fais quoi avec l’IA ?
Cette semaine j’ai le plaisir d’interviewer Antoine, désormais en charge de rubrique “news de la semaine”.
Salut Antoine, peux-tu te présenter ?
Salut Gilles, alors mon passe-temps et aussi mon job c'est le marketing et le e-commerce. Je me suis notamment "T-shaped" dans la pub digitale, l'analytics et le tracking. Je suis également tombé dans le terrier du web3 il y a 3/4 ans. Mais là c'est plus pour le plaisir tout en essayant de faire fructifier mon capital. Enfin je suis aussi un grand passionné de sport, que ce soit en (tele)-spectateur ou en pratiquant .
J'ai pratiqué plusieurs sports en compétition, notamment le triathlon à un niveau national. Actuellement je cours 3 fois par semaine et je fais 2 à 3 séances de crossfit.
Comment as-tu découvert les outils d'intelligence artificielle générative ?
J'ai toujours été un grand fan d'IA en général depuis au moins 10 ans. J'ai pris des cours sur Coursera et Udemy pour faire du machine learning et du deep learning. J'ai aussi participé à des concours d'IA sur Kaggle et Analytics Vidhya .
Pour la branche générative de l'IA je l'ai découvert l'IA générative avec GPT2 ! Bon à l'époque le tool était déjà impressionnant mais on ne pouvait pas non plus en faire grand chose.

En gros tu écrivais un début de phrase et il t'écrivait une suite de plusieurs paragraphes . C'était très cohérent mais tu pouvais difficilement maîtriser la sortie et ça partait vite en hallucinations .
Donc j'ai rapidement laché l’outil et je l'ai redécouvert le fameux 30 novembre 2022 !
Quelqu'un a laissé un message sur un groupe WhatsApp de e-commerçants en disant qu'il y avait un nouveau tool de génération de contenu qui allait tout révolutionner et mettre au chômage les rédacteurs .
Je l'ai un peu charrié car je connaissais déjà GPT et a l'époque il y avait aussi Jarvis AI, un tool d'IA pour le SEO qui permettait de générer des textes , mais qui passait pas trop auprès de Google.
Puis en testant je me suis rendu compte qu'il avait pas forcement tort 🙂
Auparavant j'avais aussi testé Midjourney , le 7 septembre 2022 exactement ( je viens de regarder dans mon historique :)). Mais là aussi c'était quand même encore trop limité pour s'en servir professionnellement
Quels outils utilises tu dans ton quotidien et quels sont tes outils préférés ?
J'utilise principalement Gemini , ChatGPT , Mistral , Claude et MidJourney .
Au quotidien je travaille principalement sur de la rédaction de fiches produits ou des comparatifs sur mes sites e-commerce . Et beaucoup aussi pour du copywriting (a.k.a. écrire pour vendre ) ou pour trouver des angles et des idées sur des campagnes marketing .

Également dès que j'ai besoin de coder même si c'est plus rare.
Mon préféré actuellement c'est Gemini même si je ne l'interroge pas pour des sujets trop experts. Mais son intégration avec Android, Google Workspace et les 2 dernières séries de Pixel Phones est canon .
Comment t'organises tu pour faire ta veille IA ?
Je lis quasiment tous les jours Bens Bites et The Rundown AI. Avec ce je pense qu'on peut capter 80/90% de l'actu IA Gen et on ne loupe pas les bangers.
Et bien sûr Générative chaque vendredi 🙂
Après je vais piocher sur X, Discord , Youtube et même Instagram où j'aime bien le coté très concis et visuel des news IA. Mais j'essaye surtout de ne pas trop tomber dans l'overdose d'infos car mon job nécessite aussi une veille permanente .
Selon toi, quels effets aura l'IA générative sur le futur de l'Art ?
Sans être un grand amateur d'Art, je pense qu'à minima l'art génératif sera et même est deja un art à part entière.
Après pour ceux pour qui l'IA générative ne peut être considéré comme de l'art , l'Art peut s'exprimer sous tellement de formes différentes qu'il restera plein de domaines dans lesquels l'IA n'aura pas accès .
Mais bon je suis surtout un Artix et ne suis pas trop légitime pour parler de ça. Même si j'adore aller voir les expos Pinault qui ont lieu juste à coté de chez moi. Par exemple je me souviens d'un tableau tout blanc avec juste un point noir dans un coin. Bon bah ça c'est vraiment le type d'art que je kiffe , car ça ne paraît être rien mais en fait ça raconte tellement de choses 🙂
Quelles sont les avancées que tu attends le plus pour le prochain semestre ?
J'attends surtout l'arrivée des agents IA. Je me sens un peu enfermé dans les LLM alors qu'il y aurait tellement a faire avec des agents .
Egalement l'intégration de l'IA à des produits pour faire des use cases très accessibles au grand public.
Sinon j'ai hâte de voir ce que vont donner GPT-5 et Sora que l'on attend depuis un petit moment maintenant !
Les (fausses) pubs IA de la semaine
L’artiste IA Alexandra Axell se démarque dans le paysage répétitif des vidéos automobiles deepfake générées par l'IA. Plutôt que de reproduire, elle relooke.
Elle dit : "J'ai imaginé une histoire, généré des images, les ai animées, puis est venu le sound design et j'ai créé la voix off, tout monté ensemble, et enfin 'upscalé'.
J'ai utilisé 7 programmes d'IA différents dont j'ignorais l'existence il y a encore un an ou deux. Quelques jours de travail, et mon test automobile est sorti. Inspiré par Tesla."
L’autre film notable est cette réalisation de Blair Vermette, un “AI Filmmaker” canadien, qui a fait le buzz avec cette pub créative et originale pour Adidas, réalisée avec Midjourney, Runway Gen-3 et un soupçon de Luma.
(le track est “Mamushi” de Megan Thee Stallion feat. Yuki Chiba)
Cette édition est terminée, merci de l’avoir lue jusqu’ici ! Si elle vous a plu, vous pouvez la partager en cliquant juste ici :
Vous pouvez également me suivre sur LinkedIn et activer la cloche 🔔, je poste régulièrement sur l’intelligence artificielle générative. Vous pouvez également me contacter pour toute proposition de création, intervention, conférence, projet, formation liée à l’intelligence artificielle générative.
Et n’oubliez pas de vous abonner pour ne rien rater des prochaines éditions 👇
J’adore ta photo avec le popcorn. 😉
Au moins il nous reste l'humour 🤘🏻 Enfin... 😉